梯度下降法
梯度下降法(Gradient descent)或最速下降法(steepest descent)是求解无约束最优化问题的一种常用方法。
假设f(x)是Rn上具有一阶连续偏导数的函数。要求解的无约束最优化问题是:
x∈Rnminf(x)
x∗表示目标函数的极小值点。
梯度下降是一种迭代算法。选取适当的初始值x(0),不断迭代,更新x的值,进行目标函数的极小化,直到收敛。
梯度的相反方向是使得函数下降最快的方向,因此在迭代的每一步,以负梯度的方向更新x的值,从而达到减少函数值的目的。
由于f(x)具有一阶连续偏导数,若第k次迭代的值为x(k),则可将f(x)在x(k)附件进行一阶泰勒展开:
f(x)=f(x(k))+gkT(x−x(k))
这里gk=g(x(k)=∇f(x(k))为f(x)在x(k)的梯度。
这里求出第k+1次迭代值x(k+1):
x(k+1)←x(k)+λkpk
其中pk是搜索方向,取负梯度方向pk=−∇f(x(k)),λk>0是步长。
在梯度下降法过程中,可以设置迭代的次数,或者迭代后的精度来决定是否结束迭代。
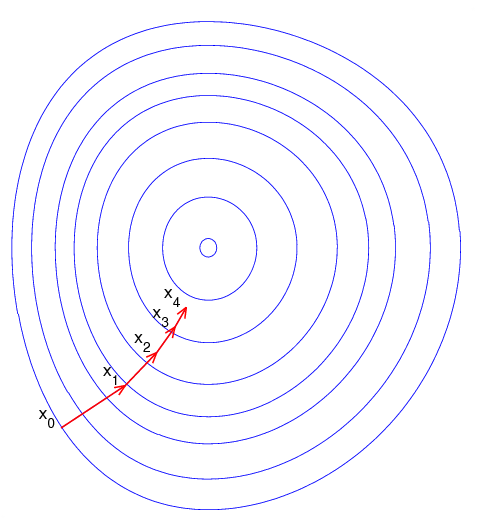
pic source: https://zh.wikipedia.org/wiki/梯度下降法
图片示例了这一过程,这里假设函数f(x,y)定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数f(x,y)为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数f(x,y)值最小的点。
当目标函数是凸函数时,梯度下降法的解是全局最优解,一般情况下,其解不能保证是全局最优解。梯度下降法的收敛速度也未必是最快的,其他的方法有牛顿法(根据二阶连续偏导数求极值)等。