反向传播算法
我们希望有个算法,能够让我们找到权重和偏置,以至于神经网络的输出y(x)能够拟合所有的训练输入x。为了量化我们如何实现这个目标,我们定义一个代价函数:
C(w,b)=2n1x∑∣∣y(x)−aL(x)∣∣2
这里w表示所有网络中权重的集合,b是所有的偏置,n是训练输入数据的个数,L表示网络的层数,aL=aL(x)是表示当输入为x时的网络输出的激活值向量,求和则是在总的训练输出x上进行的。符号∣∣v∣∣是指向量v的模。我们把C称为二次代价函数;有时也别称为均方误差或者MSE。
代价函数C(w,b)是非负的,因为求和公式中的每一项都是非负的。此外,当对于所有的训练输入x,y(x)接近于输出a时,代价函数的值相当小,即C(w,b)≈0。
反向传播算法给出了一个计算代价函数梯度的的方法:
- 输入x:为输入层设置对应的激活值a1
- 前向传播:对每个l=2,3,...,L计算相应的的zl=wl⋅a(l−1)+bl和al=σ(zl)
- 输出层误差δL:计算向量δL=∇aC⨀σ′(zL)
- 反向误差传播:对每个l=L−1,L−2,...,2,计算δl=((w(l+1)T)δ(l+1))⨀σ′(zL)
- 输出:代价函数的梯度由∂Wjkl∂C=akl−1δjl和∂bjl∂C=δjl得出。
反向传播算法的证明
两个假设
反向传播算法的目标是计算代价函数C分别关于w和b的偏导数∂Wjkl∂C和∂bjl∂C。为了让方向传播可行,我们需要做出关于代价函数的两个主要假设。
第一个假设就是代价函数可以被写成一个在每个训练样本x上的代价函数Cx的均值C=n1x∑Cx。对于二次代价函数,每个独立的训练样本的代价是Cx=21∣∣y(x)−aL(x)∣∣2,这个假设对于其他的代价函数也必须满足。需要这个假设的原因是反向传播实际上是对一个独立的训练样本计算了∂w∂Cx和∂b∂Cx,然后通过在所有的训练样本上进行平均化获得∂w∂C和∂b∂C。
第二个假设就是代价可以写成神经网络输出的函数
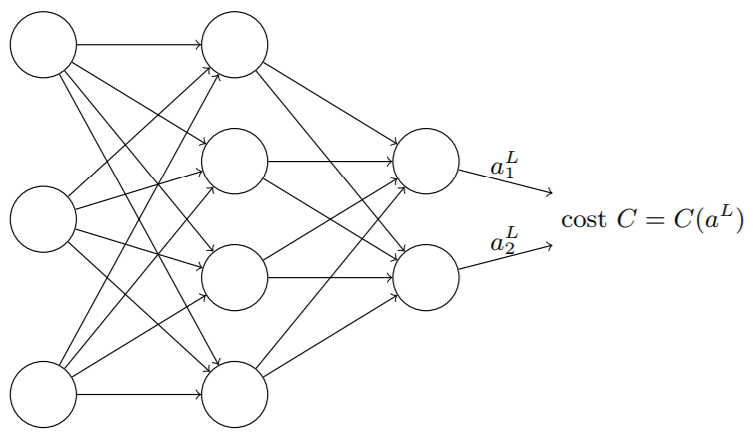
如图所示,将代价函数C看成仅有输出激活值aL的函数。
Hadamard乘积
Hadamard 乘积是按元素乘法的运算
[12]⊙[34]=[1∗32∗4]=[38]
假设s和t是两个相同维度的向量,那么我们使用s⊙t来表示按元素的乘积。所以s⊙t的元素就是(s⊙t)j=sjtj。
反向传播的四个基本方程
反向传播其实是对权重和偏置变化影响代价函数过程的理解。最终的含义就是计算偏导数∂Wjkl∂C和∂bjl∂C。为了计算这些值,我们先引入一个中间量δjl,这个称之为在lth的第jth个神经元上的误差。反向传播将给出计算误差δjl的流程,然后将其关联到计算上面两个偏导数上面。
假定在lth层的第jth神经元上,对神经元的带权输入增加很小的变化Δzjl,这使得神经元的输出由σ(zjl)变成σ(zjl+Δzjl),这个变化会向网络后的层进行传播,最终导致整个代价产生∂zjl∂CΔzjl的改变。 假如∂zjl∂C是一个很大的值(或正或负),那么可以通过选择与其相反的符号的Δzjl来降低代价。相反如果∂zjl∂C是一个接近于0的值,这时候并不能通过调整输入zjl来改善多少代价。所以这里有个启发式的认识,∂zjl∂C是神经元的误差度量。
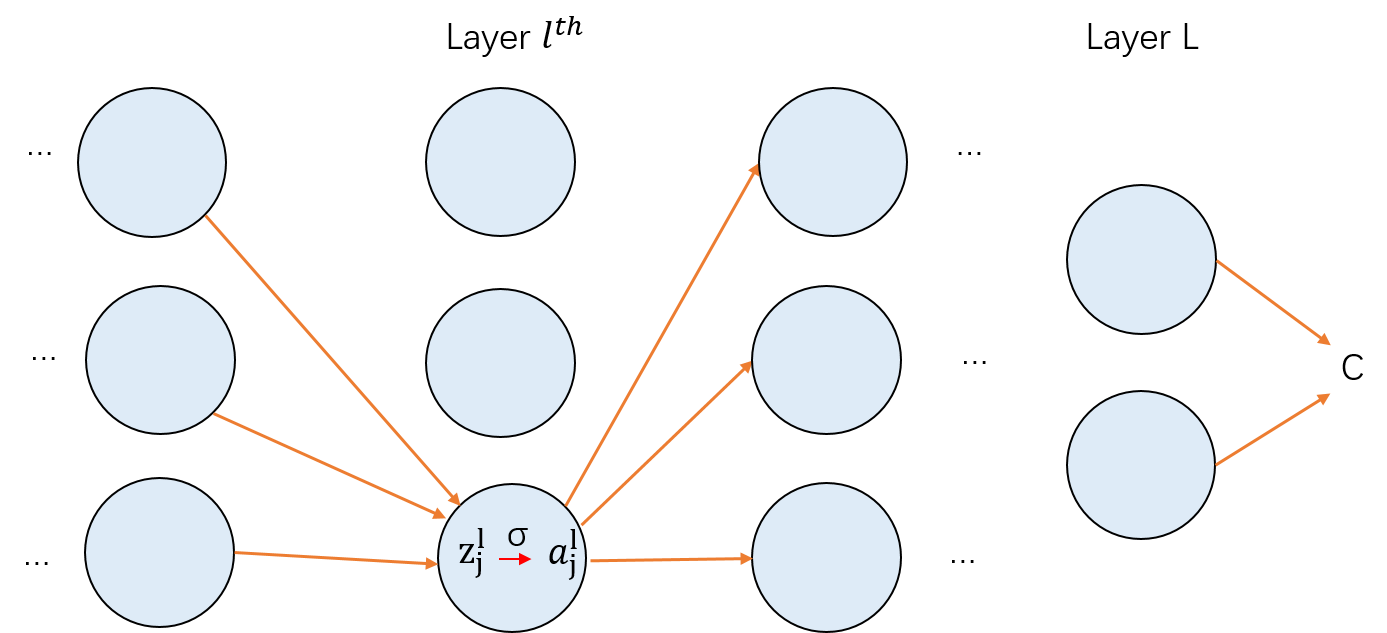
按照上面的描述,我们定义lth层的第jth个神经元的上的误差δjl为
δjl=∂zjl∂C
我们使用δl表示关联于l层的误差向量。
接下来我们介绍四个基本方程。