卷积神经网络的介绍
卷积 (convolutional)神经网络采用了三个基本概念:局部感受野(local receptive fields),共享权重(shared weights),和混合(pooling)。让我们逐个看一下:
局部感受野
第一个隐藏层的每个神经元会连接到一个输入神经元的一个小区域,例如一个 5x5 的区域,对应于25个输入像素。
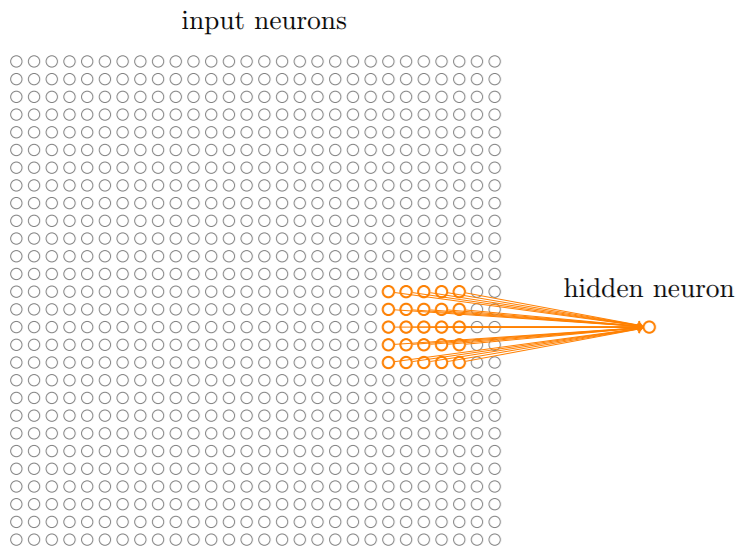
这个输入图像的区域被称为隐藏神经元的局部感受野。它是输入像素上的一个小窗口,每个连接学习一个权重。而隐藏神经元同时也学习一个总的偏置。可以把这个特定的隐藏神经元看作是在学习分析它的局部感受野。
然后在整个输入图像上交叉移动局部感受野。对于每一个局部感受野,在第一个隐藏层中有一个不同的隐藏神经元。如果有一个28x28的输入图像,5x5的局部感受野,那么隐藏层中就会有24x24个神经元。这个是因为我们只能把局部感受野横向移动23个神经元。
局部感受野有时候会用不同的跨距。
共享权重和偏置
上面每个隐藏神经元都使用同一个权重和偏置。换句话说,对于第个隐藏神经元,输出为:
这里是神经元的激活函数,是偏置的共享值。是一个共享权重的5x5数组,我们使用表示位置为的输入激活值。这意味着第一个隐藏层的所有神经元检测完全相同的特征,只是在输入图像的不同位置。
我们有时候把从输入层到隐藏层的映射称为一个特征映射。定义特征映射的权重称为共享权重,偏置称为共享偏置。共享权重和偏置经常被称为一个卷积核或者滤波器。
为了完成图像识别,我们需要超过一个特征映射。所以一个完整的卷积层由几个不同的特征映射组成。
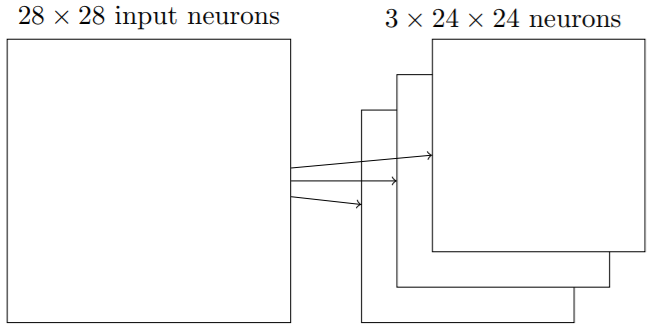
上面的例子中有3个特征映射。在实践中卷积网络可能使用很多的特征映射。
混合层
混合层通常紧接在卷积层之后,它做的是简化从卷积层输出的信息。详细的说,一个混合层取得从卷积层输出的每一个特征映射并从它们准备一个凝缩的特征映射。
例如:混合层的每个单元可能概括了前一层的比如2x2的区域。一个常见的混合的程序称为最大值混合(max pooling),在最大值混合中,一个混合单元简单地输出其2x2输入区域d额最大激活值。

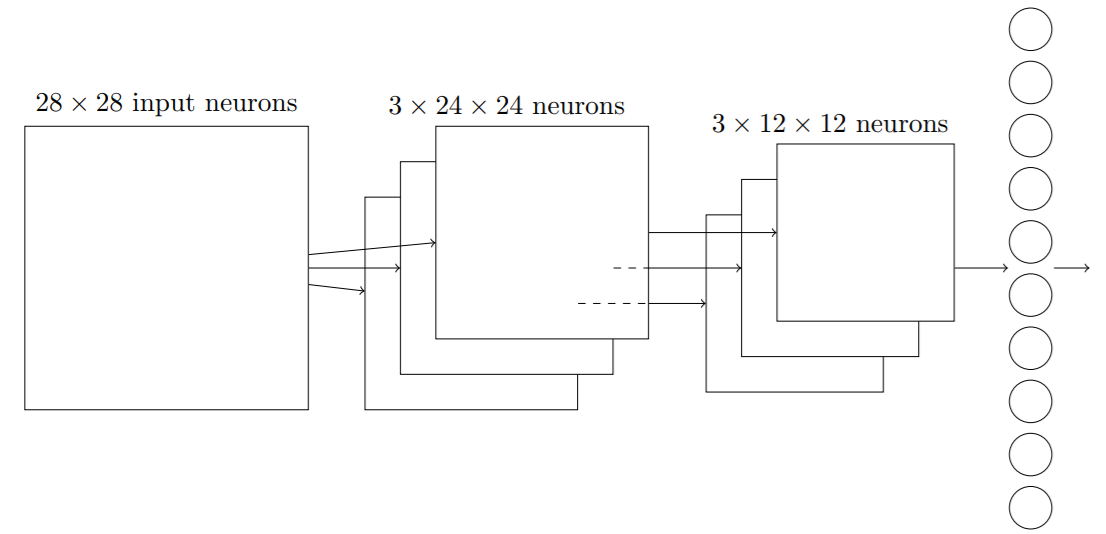
卷积层有24x24个神经元输出,混合后我们得到12x12个神经元。
卷积层通常包含超过一个特征映射,我们将最大值混合分别应用于每个特征映射,所以如果有三个特征映射,组合在一起的卷积层和最大混合层看起来像这样:
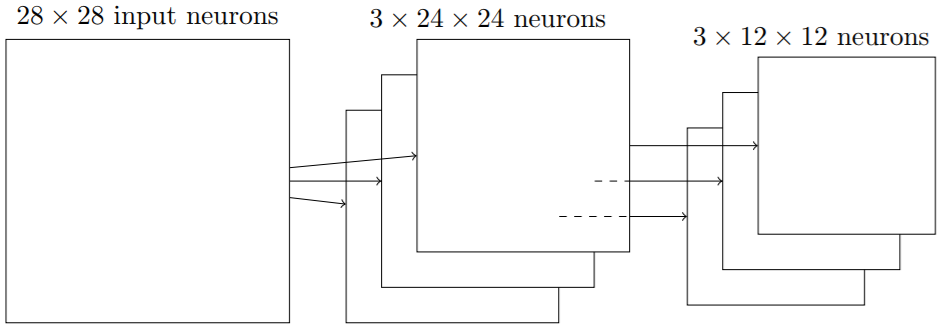
最后综合在一起:我们现在可以把这些思想都放在以一起构建一个完整的卷积神经网络,它包含一个额外的一层10个输出神经元,对应于10个可能的数字。网络最后连接的层是一个全连接层。