决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构。通常包含3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树模型
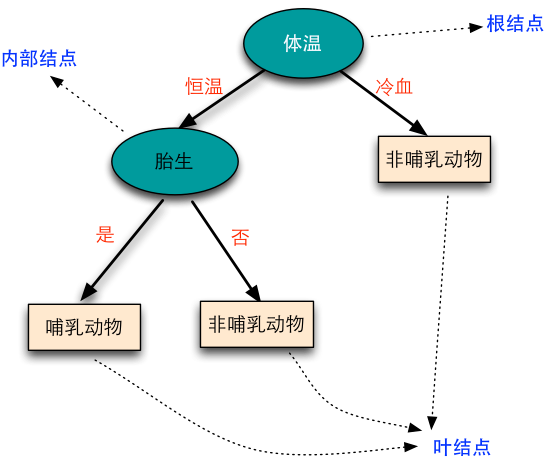
分类决策树树模型是一种描述对实例进行分类的树形结构。决策树由节点(node)和有向边(directed edge)组成。节点有两种类型:内部节点(internal node)和叶节点。内部节点表示一个特征或属性,叶节点表示一个类。
用决策树分类,从根节点开始,对实例的某个特征进行测试,根据测试的结果,将实例分别到其子节点;这时每个子节点对于着该特征的一个取值,如此递归直到叶节点,最后将实例分到叶节点的类中去。示例:
决策树学习
假定给定训练数据集
其中为输入实例(特征向量),为特征个数,为类标记,,为样本容量。学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习的损失函数通常是正则化的极大似然函数,决策树学习的策略是以损失函数为目标函数的最小化。当损失函数确定后,学习问题就变为在损失函数意义下选择最优决策树的问题。但是从所有的决策时中选取最优决策树是NP完全问题,所以现实中通常采用启发式方法,近似求解这一最优化问题,得到次最优的解。
学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有个最好的分类,这个过程对应着特征空间划分,也对应着决策树的构建。
开始时,将所有训练数据都放在根节点,然后选择一个最优特征,然后将数据集分割成子集,如果某个子集里面的数据能够被基本正确分类,则构建叶节点;如果某个子集不能被正确分类,则继续选择一个新的最优特征,继续分割数据,一直递归下去,直到所有的数据集被正确分类,或没有合适的特征为止。
以上方法对未知的数据未必有好的分类能力,可能发生过拟合现象,需要对生成的决策树进行剪枝,使得它有更好的泛化能力。
总结下来,学习算法包括 特征选择->决策树生成->决策时剪枝的过程。