Regularization 规范化,正则化
L2 规范化
regularization(规范化,正则化)有时候被称为权重衰减(weight decay)
L2规范化的想法是增加一个额外的项到代价函数上,这个项叫做规范化项。
其中第一项就是常规的交叉熵d额表达式,第二项是所有权重的平方和。然后用一个因子进行量化调整,其中称为规范化参数,而就是训练集合的大小。需要注意的是,规范化项里面不包含偏置。
也可以对其他代价函数进行规范化,比如二次代价函数
两者都可以写成
其中就是原始的代价函数。
计算对网络中所有权重和偏置的偏导数
在反向传播中,梯度下降的偏置学习规则不会发生变化,权重的学习规则发生了变化。
这个和通常的梯度下降学习规则相同,除了通过一个因子重新调整了权重,这种调整有时候被称为权重衰减,因为它使权重变小。
如果使用平均个训练样本的小批量的数据来估计权重,则为了随机梯度下降的规范化学习规则就变成了
其中后一项是在训练样本的小批量数据上进行的。
L1 规范化
这个方法是在非规范化的代价函数上加一个权重绝对值的和:
凭直觉的看,这个和L2规范化相似,惩罚大的权重,倾向于让网络优先选择小的权重,当然,L1规范化和L2规范化并不相同,所以我们不应该期望从L1规范化得到完全相同的行为,让我们试着理解使用L1规范化训练的网络和L2规范化训练的网络所不同的行为。
求代价函数的偏导数,我们得到
其中就是的正负号,即为正时为,为负数时为,得到随机梯队下降的学习规则
对比L2的更新规则可以发现,两者权重缩小的方式不同。在L1规范化中,权重通过一个常量向进行缩小,在L2规范化中,权重通过一个和成比例的量进行缩小。所以当一个特定的权重绝对值很大时,L1规范化的权重缩小的要比L2规范化小的多。相反,当yi个特定的权重绝对值很小时,L1规范化的权重缩小得要比L2规范化大得多。最终的结果是:L1规范化倾向于聚集网络的权重在相对少量的高重要度连接上,而其他权重就会被驱使向接近。
在时,偏导数未定义,原因在于函数在时,是一个直角,我们约定这时。
弃权(Dropout)
弃权(Dropout)是一种相当激进的技术,相比于L1,L2规范化不同,弃权技术并不依赖对代价函数的修改。而是在弃权中我们改变了网络的本身。使用弃权技术时,我们会从随机(临时)地删除网络中的一半神经元开始,同时让输入层和输出层的神经元保持不变。
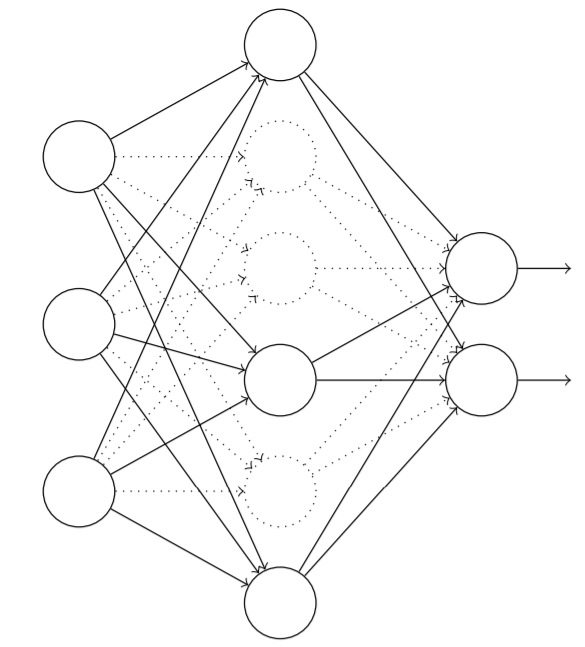
我们前向传播输入,通过修改后网络,然后反向传播,同样通过这个修改后的网络。在一个小批量数据上进行这个步骤后,我们有关的的权重和偏置进行更新。然后重复这个过程。首先恢复被弃权的神经元,然后选择一个新的随机的隐藏神经元的子集进行删除,计算对一个不同的小批量数据的梯度,然后更新权重和偏置。
通过不断地重复,我们的网络学习到一个权重和偏置的集合。当然这些权重和偏置也是在一半的隐藏神经元被弃权的情况下学习到的。当我们实际运行整个网络时,两倍的隐藏神经元被激活,为了补偿这个,我们将隐藏神经元的出去的权重进行减半处理。
L2 改进前后代码对比:
def update_mini_batch(self, mini_batch, eta, lmbda, n):
"""Update the network's weights and biases by applying gradient
descent using backpropagation to a single mini batch. The
``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is the
learning rate, ``lmbda`` is the regularization parameter, and
``n`` is the total size of the training data set.
"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
改进后的代码只是在梯度下降更新权重的时候多加了' (1-eta*(lmbda/n))*w'