权重初始化
创建了神经网络之后,我们需要进行权重和偏置的初始化,之前的方式是根据独立高斯随机变量来选择权重和偏置,其被归一化均值为,标准差为。
我们来看看这样的初始化的网络。假设我们有一个使用大量输入神经元的网络,比如1000个,假设我们已经使用归一化的高斯分布初始化了连接第一个隐藏层的权重。现在我们将注意力集中在这一层的连接权重上,忽略网络的其他部分。
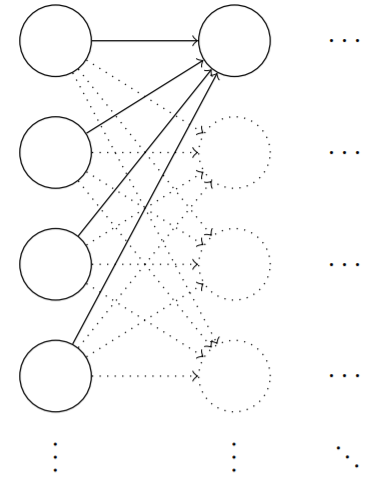
为了简化,假设我们使用训练输入,其中一半的输入神经元为,另一半的神经元输入为,让我们考察隐藏神经元的输入带权和:
其中500个项消去了,所以是遍历总共501个归一化的高斯随机变量和,其中包含500个权重项和额外的1个偏置项。因此本身是一个均值为0,标准差为的高斯分布。其实是一个非常宽的高斯分布:
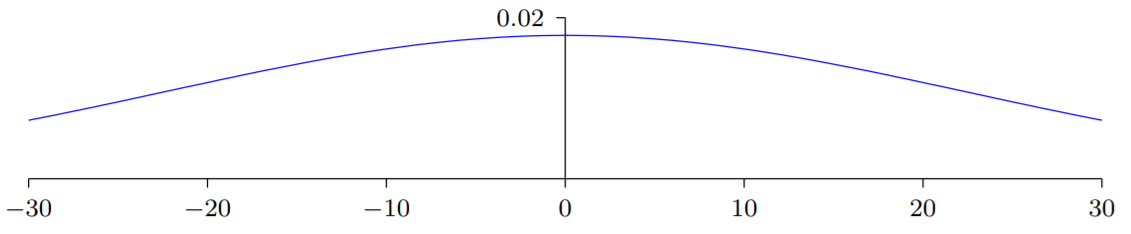
我们可以从图中看出变得非常大,这样的话,隐藏神经元的输出就会接近于或,也就表示我们的隐藏神经元会饱和。所以当出现这样的情况时,在权重中进行微小的调整仅仅会给隐藏神经元的激活值带来极其微弱的改变。而这种微弱的改变也会影响剩下的神经元,然后会带来相应的代价函数的改变。结果就是,这些权重在我们进行梯度下降算法时,学习的非常缓慢。
如何避免这种类型的饱和,最终避免学习速度的下降?
假设我们有个输入权重的神经元,我们会使用均值为,标准差为的高斯随机分布初始化这些权重。也就是说,我们会向下挤压高斯分布,让我们的神经元更不可能饱和。我们会继续使用均值为0,标准差为1的高斯分布来对偏置进行初始化。有了这些设定,带权和
仍然是一个均值为0,不过有尖锐峰值的高斯分布。假设我们有500个值为0的输入和500个值为1的输入,那么可以证明是服从均值为0,标准差为的高斯分布。()
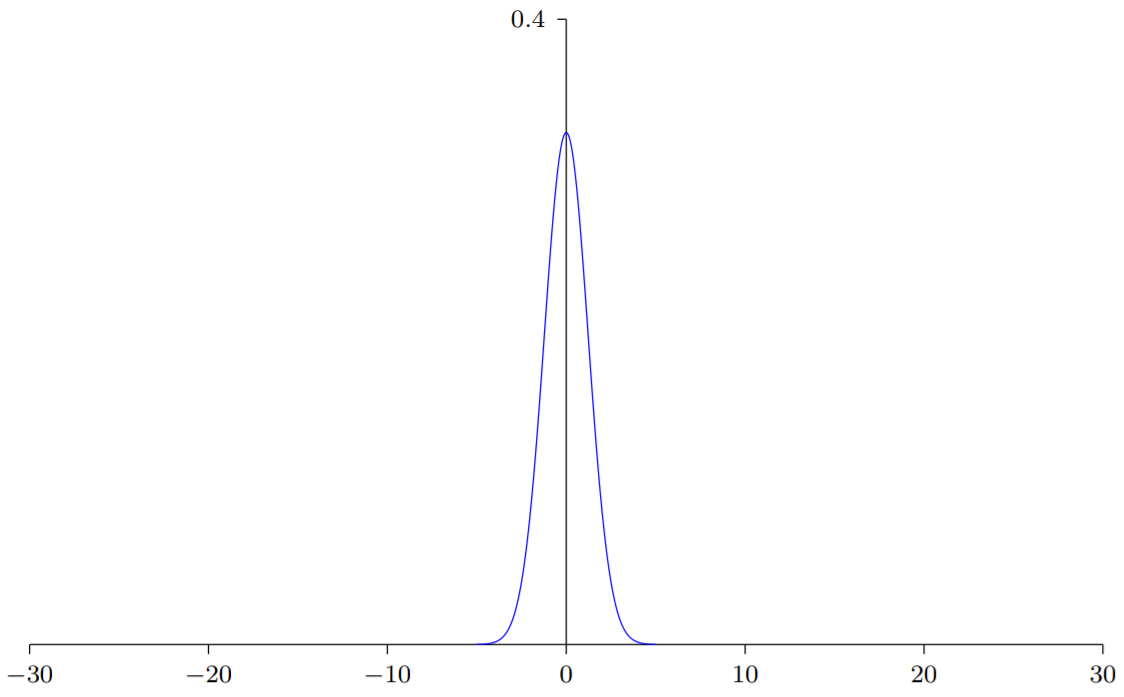
这样的一个神经元不可能饱和,因此也不太可能遇到学习速度下降的问题。
下面是两种方式的比较:
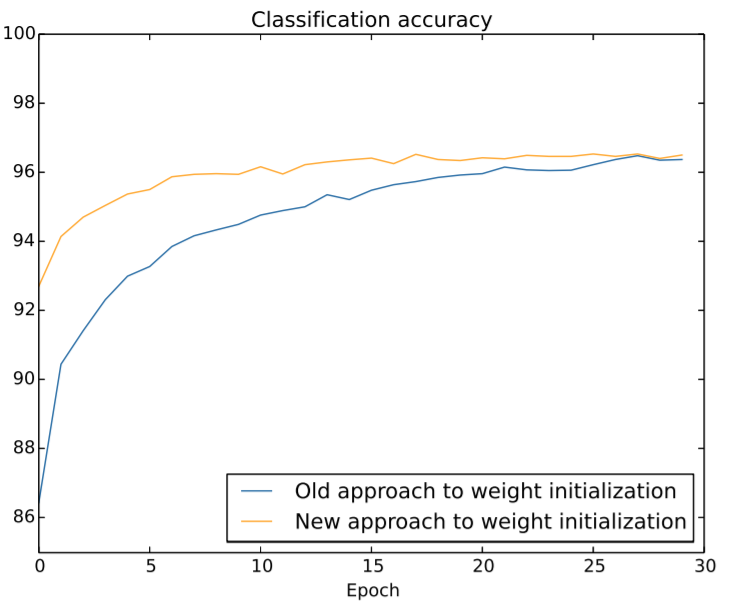
改进后的权重初始化代码对比
def default_weight_initializer(self):
"""Initialize each weight using a Gaussian distribution with mean 0
and standard deviation 1 over the square root of the number of
weights connecting to the same neuron. Initialize the biases
using a Gaussian distribution with mean 0 and standard
deviation 1.
Note that the first layer is assumed to be an input layer, and
by convention we won't set any biases for those neurons, since
biases are only ever used in computing the outputs from later
layers.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def large_weight_initializer(self):
"""Initialize the weights using a Gaussian distribution with mean 0
and standard deviation 1. Initialize the biases using a
Gaussian distribution with mean 0 and standard deviation 1.
Note that the first layer is assumed to be an input layer, and
by convention we won't set any biases for those neurons, since
biases are only ever used in computing the outputs from later
layers.
This weight and bias initializer uses the same approach as in
Chapter 1, and is included for purposes of comparison. It
will usually be better to use the default weight initializer
instead.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
其中 large_weight_initializer 是改进前,default_weight_initializer 是改进后,只是多了除以 np.sqrt(x)