感知机学习算法
感知机学习问题转化为求解损失函数的最优化问题,最优化的方法就是随机梯度下降法。
1. 学习算法的原始形式
给定一个训练数据集T={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))},其中,x(i)∈X=Rn,y(i)∈Y={+1,−1},i=1,2,...,m,求参数w,b,使得其为以下损失函数极小化的解:
w,bminL(w,b)=−x(i)∈M∑y(i)(w⋅x(i)+b)
其中M为误分类点的集合。
假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度由
∇wL(w,b)=−x(i)∈M∑y(i)x(i)
∇bL(w,b)=−x(i)∈M∑y(i)
给出。
1.1 随机梯度下降算法:
输入:训练数据集T={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))},其中,x(i)∈X=Rn,y(i)∈Y={+1,−1},i=1,2,...,m,学习率为η(0<η⩽1)
输出:w,b:感知机模型f(x)=sign(w⋅x+b)
- 选取初始值w0,b0
- 在训练集中选取数据(x(i),y(i))
- 如果y(i)(w⋅x(i)+b)⩽0,则w←w+ηy(i)x(i),b←b+ηy(i)
- 转至步骤(2),直至训练集里面的每个点都不是误分类点,这个过程中训练集中的点可能会被重复的选中并计算。
1.2 直观的解释
当出现误分类点时,则调整w,b,更正超平面的方向,使其稍微转向正确的方向。

1.3 算法的收敛性
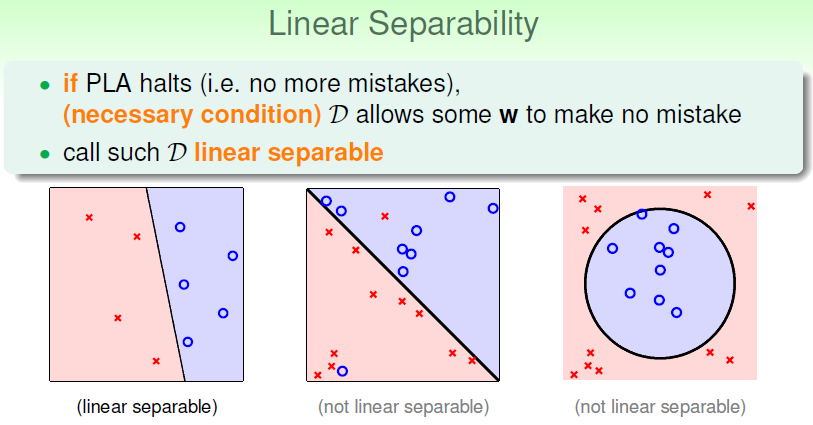
可以证明,对于线性可分的数据集,感知机学习算法经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平面及感知机模型。
2.学习算法的对偶形式
对偶形式的基本想法是,将w和b表示为实例向量x(i)和标记y(i)的线性组合的形式,通过求解其系数而求得w和b。
从上面的算法中可假设初始值w0,b0均为0。对某个误分类点(x(i),y(i))经过w←w+ηy(i)x(i)和b←b+ηy(i)迭代修改,假设修改了k次后,w,b 关于该误分类点的最后的总增量为αiy(i)x(i)和αiy(i),这里αi=kiη。对于训练集中的每一个点都有αi,所有的训练数据点的分量构成向量α=(α1,α2,...,αm)T,这样最后得到的w,b可以分别表示为(有的αi可能为0):
w=i=1∑mαiy(i)x(i)=i=1∑mkiηy(i)x(i)
b=i=1∑mαiy(i)=i=1∑mkiηy(i)
2.1 算法的对偶形式
输入:线性可分的数据集T={(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))},其中x(i)∈X=Rn,y(i)∈Y={+1,−1},i=1,2,...,m,学习率η(0<η⩽1)
输出:α,b;感知机模型f(x)=sign(j=1∑mαjy(j)x(j)⋅x+b),其中α=(α1,α2,...αm)T
- 选取初始值α=(0,0,...,0),b=0
- 在训练集中选取数据(x(i),y(i))
- 如果y(i)(j=1∑mαjy(j)x(j)⋅x(i)+b)⩽0,则αi←αi+η,b←b+ηy(i),也就是每次只更新向量α的第i个分量
- 转至步骤(2),直到没有误分类点为止。
观察可以看到步骤3中每次更新的x(j)⋅x(i)可以事先计算好并以矩阵的形式存储,那么就不需要每次都计算,
这样的矩阵称为Gram矩阵(Gram matrix):
G=[x(i)⋅x(j)]m×m
G=⎣⎢⎢⎢⎢⎡x(1)⋅x(1)x(2)⋅x(1)x(3)⋅x(1)...x(m)⋅x(1)x(1)⋅x(2)x(2)⋅x(2)x(3)⋅x(2)x(m)⋅x(2)x(1)⋅x(3)x(2)⋅x(3)x(3)⋅x(3)x(m)⋅x(3)............x(1)⋅x(m)x(2)⋅x(m)x(3)⋅x(m)x(m)⋅x(m)⎦⎥⎥⎥⎥⎤
则关于j=1∑mαjy(j)x(j)⋅x(i)的计算,j=1∑mαjy(j)x(j)⋅x(i)=j=1∑mαjy(j)G[i,j]=∑α∘y∘G[i],即三个向量中每个元素相乘再做和运算。
参考:林轩田,机器学习基石